Sharding是一种数据层架构,其中数据在独立数据库中水平分区。
每个数据库都托管在具有自己的本地资源(CPU,内存,闪存或磁盘)的专用服务器上。 在这种配置中的每个数据库称为碎片。 所有分片一起组成一个逻辑数据库,称为分片数据库(SDB)。
水平分区涉及跨分片拆分数据库表,以便每个分片包含具有相同列但行的不同子集的表。以这种方式分割的表也称为分片表。
下图显示了跨三个分片水平分区的表。
图1-1跨越碎片的表格的水平分区

横跨碎片的水平分区”的描述
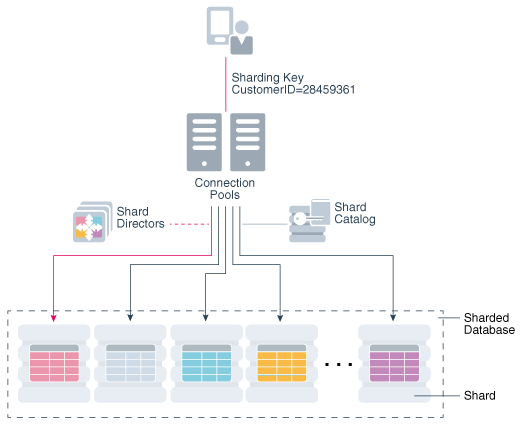
Oracle sharding的架构
分片基于无共享硬件基础架构,它消除了单点故障,因为分片不共享物理资源,如CPU,内存或存储设备。碎片在软件方面也松散耦合; 他们不运行集群件。
碎片通常托管在专用服务器上。这些服务器可以是商用硬件或工程系统。分片可以在单实例或Oracle RAC数据库上运行。它们可以放置在本地,云端或混合本地和云配置中。
从数据库管理员的角度来看,SDB由多个数据库组成,这些数据库可以集体或单独管理。但是,从应用程序的角度来看,SDB看起来像一个数据库:这些分片中的分片数量和数据分布对数据库应用程序是完全透明的。
分片适用于适用于分片数据库体系结构的自定义OLTP应用程序。使用分片的应用程序必须具有明确定义的数据模型和数据分布策略(一致的散列,范围,列表或复合),主要使用分片键访问数据。一个分片键的实例包括customer_id,account_no,或country_id。
Oracle 18c关于sharding的资料链接:
目前我们正在帮一个客户解决大表的分布式分区问题,采用的oracle shaerding 技术正在测试中,后续分享完整的过程。

